
NS beloofde dat te regelen.
dit jaar weer niet.
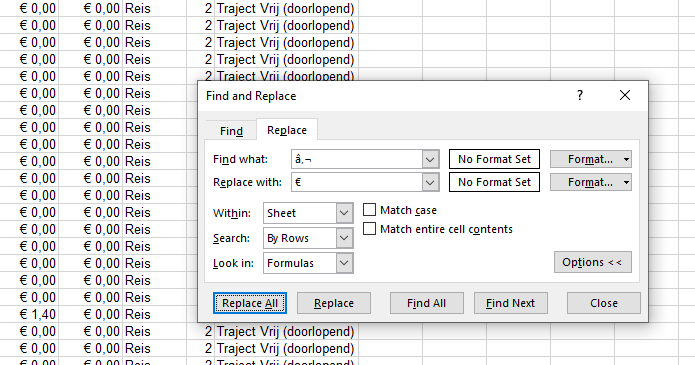
omzetten is lastig. als je alles in kolommen hebt is de kolom met EURO betalingen rommeling met rare voortekens.
hoe lossen we dit nu weer op?
Beste antwoord door Momo
Bekijk origineelBeste antwoord door Momo
Bekijk origineel +3
+3
+3
+3
+3
beste NS support,
weer een jaar verder. net weer de truc moeten herhalen van .csv naar excell en dan â naar €. Na 15 minuten met behulp van de tips van vorig jaar gelukt.
De herhaalvraag blijft: kan NS in Corona tijd er misschien een IT er opzetten om dit even voor de reizigers te fixen.
we zijn toch klanten en geen IT deskundigen die aan het werk gehouden moeten worden? zelfs de banken hebben tegenwoordig excell.
veel dank
+3
Dan heeft u zeker een andere bank dan ik heb, zowel bij ING als Rabo heb ik bij downloaden van de afschriften de keuze tussen CSV en PDF, en niet Excel. Bij die 2 banken is er dan wel geen euro-teken voor het bedrag, maar alleen een getal in de CSV file.
Misschien een idee om de tips ergens te noteren of uit te printen zodat u het makkelijk kunt vinden. De reden voor gebruik van CSV is eerder al gegeven in het topic waar Robert vorig jaar naar linkte. Het is dus een keuze, niet een fout die gefixt moet worden.
Bedankt voor je reactie momo. mijn bank: good old abnamro. op dit punt klantgericht. ik zeg overigens niet dat het een fout is. het gaat om de vraag of je met klanten communiceert of met IT specialisten.
De fout en oplossing is helemaal niet zo moeilijk. Het bestand dat gegenereerd wordt is in het formaat ‘UTF-8’ echter zonder BOM (Byte Order Mark).
Windows (en dus Excel) vereisen echter als de karakterset UTF-8 is dat deze dan altijd voorzien is van zo'n Byte Order Mark. De eerste 3 tekens moeten een specifieke waarde hebben.
Zie ook: https://en.wikipedia.org/wiki/Byte_order_mark
Als je het gedownloade bestand opent in notepad++ en dan kiest voor converteren naar UTF-8 met BOM en daarna opent dan gaat het wel goed. Volgens mij gaat MsExcel er vanuit dat als er geen BOM aanwezig is dat het ASCII is en geen UTF-8.
Dus inderdaad iets dat een ontwikkelaar aan Mijn-Ns gemakkelijk kan oplossen door bij de export in UTF-8 deze 3 tekens toe te voegen.
Volgens mij gaat MsExcel er vanuit dat als er geen BOM aanwezig is dat het ASCII is en geen UTF-8.
Dus inderdaad iets dat een ontwikkelaar aan Mijn-Ns gemakkelijk kan oplossen door bij de export in UTF-8 deze 3 tekens toe te voegen.
Dat zou kunnen, maar dat is natuurlijk een foute aanname; ASCII is ook UTF-8 (andersom niet), en UTF-8 zonder BOM is nog steeds valide UTF-8. Excel zou beter UTF-8 kunnen aannemen, tenzij de BOM er is (die dan evt. een andere encoding aangeeft).
Aan de andere kant zou NS ook een BOM kunnen toevoegen, maar dan alleen als er niet-ASCII UTF-8 karakters in de data zitten zoals euro-tekens. Dan kan oude software die alleen ASCII ondersteunt nog steeds overweg met ‘eenvoudige’ bestanden.
Mijn eerste inschatting was ook dat Excel dit beter zou moeten doen, ik heb daar zelfs al eens een bug voor ingediend bij MS. Echter is MS van mening dat UTF-8 met BOM de enige juiste methode is omdat je anders geen onderscheid kan maken tussen ASCII en UTF-8(zonder BOM en zonder UTF-8 tekens).
Want hoewel een mens prima kan inschatten of de ASCII weergave van dit voorbeeld onjuist is kan een computer dit niet. Want en computer weet niet dat het logisch is om op dit punt een Euroteken te plaatsen en niet het de â en nog een teken. Dus aan het bestand zelf kan je niet zien dat het UTF-8 moet zijn. Alleen een BOM toevoegen als er gebruik gemaakt is van de UTF-8 karakters zou het voor dit geval niets uit maken omdat er altijd een euro teken in het bestand staat (als UTF-8)
Een programma dat nu nog geen UTF-8 kan lezen is echt aan vervanging toe, ik kan me niet voorstellen dat daar nog actuele versies van zijn die onderhouden worden.
+3
Via een UTF-8 import in Excel gaat het prima. Zie hier voor hoe. Wellicht helpt zo’n BOM header ook om voor die import een paar stappen over te slaan (handmatig UTF-8 kiezen).
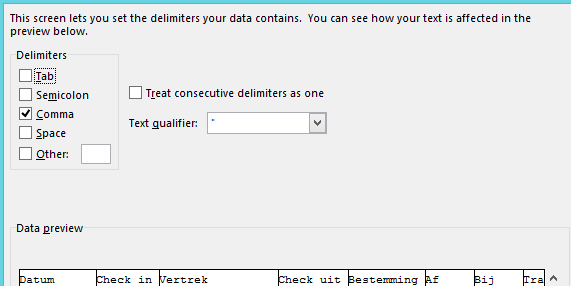
Voor de rest is het (voor alle spreadsheetprogramma's) erg eenvoudig op te lossen door in het csv bestand geen komma maar een puntkomma als scheidingsteken te gebruiken, dan kan men het bestand genereren zonder “quotes” om elke waarde heen (waardoor het een tekstveld wordt zoals ‘€ 3,00’ of ‘3,00’ waar je vervolgens niet mee kunt rekenen). In onderstaande reactie staat een voorbeeldbestand (oude opmaak csv bestand uit Mijn NS).
Dus aan het bestand zelf kan je niet zien dat het UTF-8 moet zijn. Alleen een BOM toevoegen als er gebruik gemaakt is van de UTF-8 karakters zou het voor dit geval niets uit maken omdat er altijd een euro teken in het bestand staat (als UTF-8)
Dat kan juist wel omdat de eerste 128 karakters van UTF-8 bestaan uit ASCII. Als nieuwe software nou gewoon UTF-8 ondersteunt, dan heb je helemaal geen BOM nodig. Ergo, het dient eigenlijk alleen om andere Unicode encodings te kunnen herkennen. Ik heb zo’n idee dat, terwijl meer dan 95% v.d. websites UTF-8 gebruikt, het Unicode consortium zich niet wil mengen in de discussie welke encoding de ‘de facto’ standaard is.
+2
202012 13 12:13
Voor het gemak nog even de link naar het eerdere topic:
Dus aan het bestand zelf kan je niet zien dat het UTF-8 moet zijn. Alleen een BOM toevoegen als er gebruik gemaakt is van de UTF-8 karakters zou het voor dit geval niets uit maken omdat er altijd een euro teken in het bestand staat (als UTF-8)
Dat kan juist wel omdat de eerste 128 karakters van UTF-8 bestaan uit ASCII. Als nieuwe software nou gewoon UTF-8 ondersteunt, dan heb je helemaal geen BOM nodig. Ergo, het dient eigenlijk alleen om andere Unicode encodings te kunnen herkennen. Ik heb zo’n idee dat, terwijl meer dan 95% v.d. websites UTF-8 gebruikt, het Unicode consortium zich niet wil mengen in de discussie welke encoding de ‘de facto’ standaard is.
Als dat zo zou zijn dan zou dit probleem niet bestaan. Excel opent het bestand alsof het ASCII is en omdat ASCII voor iedere 2 bytes een een karakter gedefinieerd heeft kan een PC niet bepalen dat het om iets anders dan ASCII gaat. Dat is het grote nadeel van ASCII, de inhoud heeft geen enkel aanduiding of het echt ascii is. Door ook UTF-8 te gebruiken zonder BOM creëer je een probleem omdat de ontvangen moet gokken of het ASCII is (met mogelijk rare tekens, maar sja dat kan best de bedoeling zijn) of UTF-8 waar deze rare tekens eigenlijk multi-byte tekens blijken te zijn.
Maar we dwalen af. Als de NS voor het merendeel van haar klanten een goed werkende export wil aanbieden kunnen ze het beste er netjes UTF-8 met BOM van maken. Los van de discussie over de zin en onzin van BOM is het gewoon zo dat het zonder BOM nu fout gaat bij de Office pakketen die heel veel gebruikt worden.
Als dat zo zou zijn dan zou dit probleem niet bestaan. Excel opent het bestand alsof het ASCII is en omdat ASCII voor iedere 2 bytes een een karakter gedefinieerd heeft kan een PC niet bepalen dat het om iets anders dan ASCII gaat. Dat is het grote nadeel van ASCII, de inhoud heeft geen enkel aanduiding of het echt ascii is. Door ook UTF-8 te gebruiken zonder BOM creëer je een probleem omdat de ontvangen moet gokken of het ASCII is (met mogelijk rare tekens, maar sja dat kan best de bedoeling zijn) of UTF-8 waar deze rare tekens eigenlijk multi-byte tekens blijken te zijn.
Je zit er naast, ASCII gebruikt slechts 1 byte per karakter en kent maar 128 tekens. https://en.wikipedia.org/wiki/ASCII
Je hebt het waarschijnlijk over ‘extended ASCII’, een wat ongelukkig gekozen naam en zeker geen standaard.
Als dat zo zou zijn dan zou dit probleem niet bestaan. Excel opent het bestand alsof het ASCII is en omdat ASCII voor iedere 2 bytes een een karakter gedefinieerd heeft kan een PC niet bepalen dat het om iets anders dan ASCII gaat. Dat is het grote nadeel van ASCII, de inhoud heeft geen enkel aanduiding of het echt ascii is. Door ook UTF-8 te gebruiken zonder BOM creëer je een probleem omdat de ontvangen moet gokken of het ASCII is (met mogelijk rare tekens, maar sja dat kan best de bedoeling zijn) of UTF-8 waar deze rare tekens eigenlijk multi-byte tekens blijken te zijn.
Je zit er naast, ASCII gebruikt slechts 1 byte per karakter en kent maar 128 tekens. https://en.wikipedia.org/wiki/ASCII
Je hebt het waarschijnlijk over ‘extended ASCII’, een wat ongelukkig gekozen naam en zeker geen standaard.
Volgens mij is het punt hier niet of het de echte ASCII is met inderdaad 128 tekens of extended. Maar dat het aangeboden bestand in UTF-8 is en niet zodanig gecodeerd dat de software van de klant hier goed mee om kan gaan en het dus verkeerd toont. Punt blijft gewoon dat het voor de NS goed zou zijn om wel de UTF-8 + BOM te gebruiken.
Verder maakt het voor mijn argumentatie niet uit of je uit gaat van 1 of 2 bytes. Was inderdaad een foutje van mij om uit te gaan van 2 bytes omdat ik al zo lang niet meer met ASCII gewerkt heb dat ik me niet kon voorstellen dat het inderdaad slechts 1 byte was.
Tja, het mooie van UTF-8 is dat de eerste 128 karakters gewoon ASCII zijn. Daar kun je standaard een BOMmetje onder leggen, maar je kunt het ook laten. Microsoft bepaalt gelukkig de standaard niet.
+3
Zonder BOM vraagt Excel bij importeren om handmatig een ‘bronbestand codering’ te kiezen uit een hele lijst mogelijkheden. Je moet dan maar weten dat het UTF-8 is, alhoewel dat wel de meest gebruikte is natuurlijk, en het voorbeeldvenstertje de uiteindelijke opmaak toont.
Is het wel duidelijk aangegeven in de header, dan kan je die handeling in ieder geval overslaan, net zoals bij Open/LibreOffice er bij geen header vanuit gegaan wordt dat het wel UTF-8 zal zijn.
+3
Niet NS gerelateerd (off-topic dus) maar oh jee!
Iemand al geprobeerd iets te declareren via de ‘nieuwe’ OV-chipkaart website?
Zie o.a. https://twitter.com/Swap_I_Chou/status/1620132926389383170
Mij lukt het ook niet, kan hooguit terug naar november 2022 en dan nog weinig.
En bij reizen op saldo weet Mijn NS natuurlijk helemaal niets over trein/bus/tram/metro ritten met andere vervoerders (of je actuele saldo, voor zover dat belangrijk is).
+2
Die website is sowieso een ramp geworden, want de reishistorie staat daar nu onder de kaartinformatie. Die bevat bij mij 42 producten waarvan 40 verlopen, dus dat is nogal een eind scrollen.
+3
Heel merkwaardig. Iedere transactie heeft een ID maar die beginnen pas bij nummer 909 en blijven gewoon doortellen in 2023. Vandaag zit ik bij ID 1175.
+3
Heel merkwaardig. Iedere transactie heeft een ID maar die beginnen pas bij nummer 909 en blijven gewoon doortellen in 2023. Vandaag zit ik bij ID 1175.
Nog even gekeken en nu kan ik in eerste instantie maar terug tot 3 december.
Bij een tweede keer handmatig periode selecteren kan je wél verder terug (en alleen geselecteerde transacties declareren werkt ook), maar echt intuitief is het niet.
Verder staat er in de gegenereerde pdf nog iets over BTW 6% (vóór 2019), maar zo ver terug kan sowieso niet (max. 18 maanden). Dat is dus totaal overbodig.
En dan verloopt na een minuut of 10 je sessie en bij opnieuw inloggen is je account 2 uur lang geblokkeerd… Ge-wel-dig! 😣
Heb je al een account? Inloggen
Nog geen account? Maak een account aan
Enter your username or e-mail address. We'll send you an e-mail with instructions to reset your password.